
Shed the SAS: Strategic Framework for Python Migration
As organizations transition toward cloud-native architectures, the migration from legacy SAS environments to Python is no longer just a coding task; it is a strategic imperative for scalability and innovation. This white paper outlines the framework for navigating this transition, focusing on maintaining predictive parity while embracing the modular flexibility of open-source ecosystems.
While the two languages share foundational similarities, successful conversion requires a nuanced understanding of algorithmic assumptions and data scrubbing variations. By shifting the focus from "exact code replication" to "functional and accuracy alignment," Kairos Solutions ensures that the resulting Python environment is not only a mirror of the past but a foundation for future AI and machine learning initiatives.
The transition from SAS to Python represents a fundamental shift in how organizations handle data science. While SAS has long been the standard for statistical analysis, the modern landscape demands the integration, community support, and cost-efficiencies offered by Python.
The Migration Challenge: Setting Realistic Expectations
The primary hurdle in code conversion is not the technical translation, but the expectation of identical outputs.
The Goal of Similarity: Organizations must understand that generating the exact same result is not always feasible.
Defining Success: A successful migration results in a model with similar predictive power and accuracy.
Contextual Expertise: Transitioning code effectively requires collaboration with experts who understand the specific data and the original modeling context.
The Technical Process: From Data to Model
I. Data Scrubbing
Data scrubbing is generally a straightforward translation process.
Functional Mapping: Most SAS Data Step logic has a direct analogue within the Python Pandas library.
Handling Complexity: Sophisticated SAS procedures may require more complex, custom Python coding to achieve the same result.
Data Integrity: In most cases, the resulting Python data will be highly similar to the original SAS output, with minor variations only occurring due to rounding or formatting.
II. Model Development
Differences between the two languages become more pronounced during the modeling phase.
Algorithmic Consistency: For algorithms like Linear Regression, results are typically consistent if the underlying data is identical.
The Randomization Factor: Differences often arise because SAS and Python use different random number generators, leading to variations in training and test data selection.
Variable Selection: Stepwise selection algorithms may utilize different internal assumptions, potentially resulting in different subsets of variables between the two models.
Heuristic Models: For Logistic Regression, Neural Networks, or Tree-Based Splitting, the built-in assumptions vary so significantly that an exact match is virtually impossible.
The Validation Framework
To ensure the integrity of the migrated code, Kairos Solutions employs a rigorous three-step validation process.
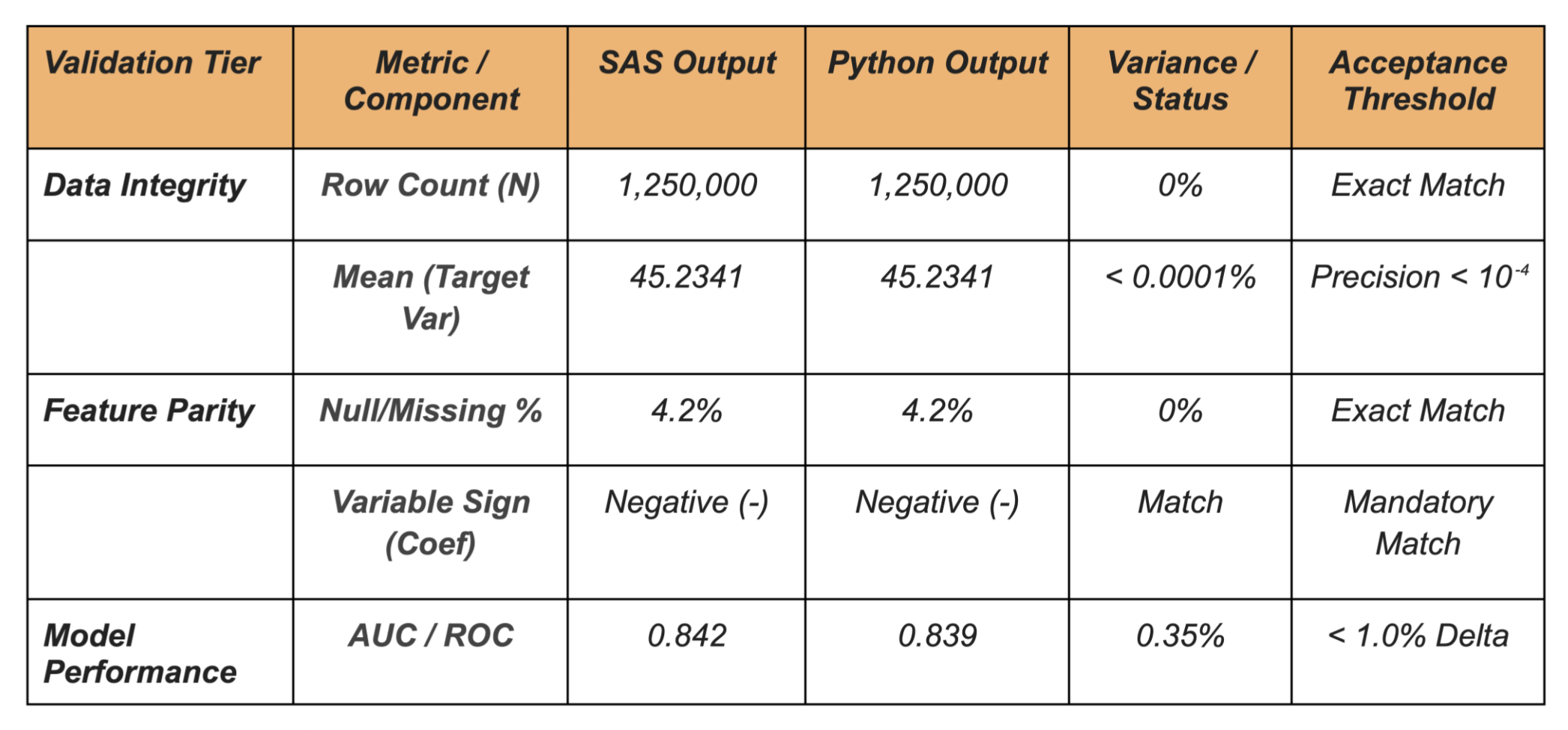
1. Structural Review: We examine model coefficients and variables to ensure they are in the same order of magnitude and share the same sign.
2. Accuracy Benchmarking: We compare global performance metrics, including ROC Curves, RMSE values, and Accuracy Scores, to verify that predictive power remains consistent.
3. Record-Level Scoring: We score a small subset of records through both the SAS and Python models. The outputs should be closely aligned; any significant variance triggers a deep-dive investigation into the source of the variation.
The Kairos Technical Validation Matrix
This matrix establishes the "Acceptable Variance" thresholds for the migration. It moves the conversation away from "perfect replication" toward "statistical equivalence."
Kairos Rules of Engagement" for Validation:
A. The Hierarchy of Precision
Not all variances are created equal.
● Data Scrubbing (Tier 1 & 2): Differences here are usually due to join logic or handling of nulls. We aim for 100% parity.
● Model Heuristics (Tier 3 & 4): Differences here are expected due to how different libraries (e.g., Scikit-Learn vs. SAS PROC LOGISTIC) handle optimization, solvers, or default penalties (L1/L2).
B. Parallel Scoring (The "Ground Truth" Test)
The final validation step involves taking a "Holdout Set" of 10,000 records. We pass these through the legacy SAS production engine and the new Python pipeline simultaneously.
● The Goal: A correlation coefficient (R^2) of > 0.99 between the two probability scores.
● The Investigation Trigger: Any record where the Python score deviates by more than 5% from the SAS score is flagged for manual audit to ensure no logic was lost in translation.
C. Deconstructing Custom SAS Macros
While standard procedures map easily to Python, legacy SAS macros often contain nested, proprietary logic that requires a structural "deconstruct and refactor" approach rather than a line-by-line translation. Our methodology involves auditing the macro's parameters and global symbol tables to recreate their functionality as modular, reusable Python functions or classes. By transitioning from string-substitution macros to object-oriented Python modules, Kairos Solutions ensures that the new codebase is not only more readable but also significantly easier to debug and maintain within a modern version-control environment.
Conclusion
"Shedding the SAS" allows your team to move beyond the constraints of legacy software without sacrificing analytical rigor. By following a structured validation path and focusing on model accuracy, Kairos Solutions ensures your transition to Python is both seamless and scientifically sound.